

Certa manhã, Mel Farnsworth estava sentado na cabine de controle da linha de montagem da Hardy Automotive Parts, bebendo sua última xícara de café antes do final do turno. Observando o gráfico do medidor de linha em seu console IHM, ele percebeu que as tendências de rendimento e eficiência da Linha 3 haviam caído para zero. Então ele olhou pela janela da sala de controle, mas a Linha 3 parecia estar funcionando normalmente. Qual era o problema então?
A linha estava funcionando perfeitamente, mas Mel não estava obtendo os dados de que precisava. Em algum lugar entre os CLPs e o display da IHM havia uma desconexão de dados. Talvez tenha sido um problema de fieldbus ou uma conexão de rede ruim. Talvez tenha sido causado por seu servidor OPC, ou possivelmente até mesmo por seu próprio sistema IHM. Seja qual for o motivo, como a conexão de dados de Mel era uma cadeia única, uma quebra na cadeia significa que ele não obteve seus dados. Para minimizar esse tipo de risco e garantir a maior disponibilidade possível, os sistemas de missão crítica costumam usar redundância.
O que é redundância?
Redundância em um sistema de controle de processo significa que parte ou todo o sistema está duplicado ou redundante. O objetivo é eliminar, tanto quanto possível, qualquer ponto de falha. Quando um equipamento ou link de comunicação falha, um componente semelhante ou idêntico está pronto para assumir o controle. Existem três tipos de sistemas redundantes, categorizados pela rapidez com que um substituto (ou reserva) pode ser colocado online. São eles: cold standby, warm standby e hot standby.
Cold standby implica que haverá um atraso significativo para colocar o sistema de substituição em funcionamento. O hardware e o software estão disponíveis, mas pode ser necessário inicializá-los e carregá-los com os dados apropriados. Imagine os velhos tempos das locomotivas a vapor. O modo cold standby era o motor extra na casa redonda que precisava ser ligado e colocado em serviço. Cold standby geralmente não é usado para sistemas de controle, a menos que os dados sejam alterados com pouca frequência.
Warm standby tem um tempo de resposta mais rápido, porque o sistema de backup (redundante) está sempre em execução e é atualizado regularmente com uma cópia recente do conjunto de dados. Quando ocorre uma falha no sistema primário, o sistema redundante pode desconectar-se do sistema com falha e conectar-se ao sistema de backup. Isso permite que o sistema se recupere rapidamente (geralmente em segundos) e continue o trabalho. Alguns dados serão perdidos durante esse ciclo de desconexão/reconexão, mas o modo de espera quente pode ser uma solução aceitável onde alguma perda de dados pode ser tolerada.
Hot standby significa que os sistemas de dados primário e secundário são executados simultaneamente e ambos fornecem fluxos de dados idênticos ao cliente downstream. O sistema físico subjacente é o mesmo, mas os dois sistemas de dados usam hardware separado para garantir que não haja nenhum ponto único de falha. Quando o sistema primário falha, a transição para o sistema secundário deve ser completamente contínua, ou “sem problemas”, sem perda de dados. O modo de espera quente é a melhor escolha para sistemas que não toleram a perda de dados de um sistema cold ou warm standby.
Um sistema OPC redundante típico
Como é a redundância em um sistema baseado em OPC? Um cenário típico teria dois servidores OPC conectados a um único dispositivo ou PLC, ou possivelmente dispositivos ou PLCs duplicados. Esses dois servidores OPC se conectariam então a algum tipo de software de gerenciamento de redundância OPC que, por sua vez, oferece uma conexão única ao cliente OPC, como uma IHM. O gerenciador de redundância é responsável por mudar para o servidor OPC secundário quando surgir algum problema com os dados provenientes do servidor OPC primário. Este cenário cria um fluxo de dados redundante desde o sistema físico até a IHM.
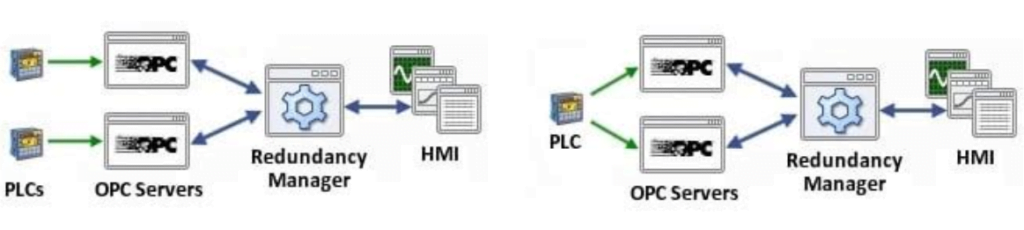
O uso mais comum de redundância para OPC é com OPC DA ou UA, mas também é possível configurar sistemas OPC A&E redundantes. Os princípios são os mesmos. Às vezes, em sistemas grandes, é necessário configurar múltiplos pares redundantes. A redundância também pode ser configurada em uma rede, usando tunelamento DCOM ou OPC. Para uma configuração em rede, o gerenciador de redundância normalmente residiria na máquina cliente OPC, para minimizar o número de possíveis pontos de falha.
Embora o modo de espera frio ou quente possa ser útil em algumas circunstâncias, normalmente um engenheiro ou integrador de sistemas que implementa um sistema OPC redundante está procurando o modo hot standby. Este é o tipo de redundância mais útil em um sistema de controle de processo e, ao mesmo tempo, o mais difícil de ser alcançado. Vamos examinar um pouco mais de perto aquela tarefa tão importante do gerenciador de redundância OPC em um sistema hot standby: fazer a troca.
Fazendo a mudança
Simplificando, um gerenciador de redundância hot-standby recebe dados de duas entradas idênticas e envia uma única saída para o cliente OPC. É função do gerente de redundância determinar sempre qual dos dois fluxos de dados é o melhor e mudar de um para o outro o mais rápido possível sempre que o status mudar. A mudança pode ser acionada por vários tipos diferentes de eventos:
- Alteração de valor de ponto único – de ou para um determinado valor, atingindo um limite, etc.
- Alteração de qualidade de ponto único – por exemplo, de “Boa” para qualquer outra qualidade OPC.
- Monitoramento de vários itens – se a qualidade ou o valor de qualquer ponto de um grupo for ruim.
- Monitoramento da taxa de mudança – se os pontos mudam de valor mais lentamente do que o esperado.
- Interrupções e tempos limite de rede – verificados com algum tipo de mecanismo de pulsação.
Uma vez ocorrida a mudança, o sistema ou o próprio gerenciador de redundância poderá ter a capacidade de enviar um alarme ou mensagem de e-mail, ou até mesmo iniciar algum tipo de programa de diagnóstico ou investigação. Também poderá registrar informações de diagnóstico sobre o estado do servidor OPC primário ou da conexão de rede. E num sistema que distingue entre entradas primárias e secundárias, muitas vezes haverá um meio de favorecer a entrada primária e voltar a ela quando possível, por vezes referido como um substituto.
Considerações práticas
A ideia de redundância para OPC não é difícil de entender, mas implementá-la exige alguma reflexão. Uma decisão inicial sobre cold, warm ou hot standby afetará todos os aspectos da implementação. A escolha do hardware e software adequados é crítica para o bom funcionamento do sistema. Uma arquitetura de sistema robusta também é importante, especialmente se a conexão for feita através de uma rede. Além de selecionar servidores OPC e planejar a infraestrutura de rede (se necessário), uma decisão importante será o software utilizado para gerenciar a redundância. Um bom software de gerenciamento de redundância deve ser fácil de usar, sem necessidade de programação. A tecnologia deve estar atualizada, capaz de rodar na versão mais recente do Windows. Deve haver uma chance mínima absoluta de perda de dados durante uma troca, mesmo através de uma rede.
A armadilha do temporizador
Na prática, não é possível obter uma comutação completamente perfeita em todos os casos, mesmo com um sistema hot standby. Por exemplo, se ocorrer uma falha de rede na conexão primária, um certo tempo passará antes que um gerenciador de redundância possa detectar essa falha. Os dados transmitidos durante esse período não chegarão, mas o gerenciador de redundância não conseguirá distinguir entre uma falha e uma pausa normal no fluxo de dados.
Muitos gerenciadores de redundância implementam temporizadores para verificar periodicamente o status da conexão de rede para tentar minimizar esse atraso, mas um mecanismo de comutação baseado em temporizadores periódicos sempre sofrerá com perda de dados. Sistemas com vários parâmetros de temporização geralmente resultarão em atrasos aditivos, onde a comutação mais rápida possível para o sistema é a soma desses atrasos de temporização. Além disso, o uso de temporizadores para detectar falhas de rede pode resultar em um problema de configuração onde o integrador do sistema deve optar pela latência de comutação contra a detecção de falhas de rede de falso positivo. Isso efetivamente se torna uma troca entre estabilidade do sistema e capacidade de resposta.
Usar temporizadores para verificar periodicamente valores ou qualidades de dados, ou sondar os servidores OPC, também é problemático porque os temporizadores introduzem latência desnecessária no sistema. Enquanto uma falha de rede deve ser detectada com base no tempo, uma alteração de valor ou qualidade de dados pode ser detectada imediatamente quando o evento ocorre. Geralmente, é melhor evitar sistemas baseados em detecção de alteração de valor baseada em tempo e usar monitoramento de objeto baseado em evento.
Monitoramento de objetos e links
Um bom gerenciador de redundância deve ser capaz de suportar tanto o monitoramento de objetos quanto o monitoramento de links. Monitoramento de objetos significa a capacidade de monitorar pontos individuais e fazer uma troca com base em um evento. Por exemplo, se uma tag watchdog designada mudar de forma significativa, como ficar negativa ou ultrapassar um limite especificado, ela pode acionar uma troca para o servidor OPC secundário. Ou talvez você queira monitorar um grupo de pontos e, se a qualidade de qualquer um deles for para “Ruim” ou “Desconectado”, você pode alternar. O monitoramento de links é especialmente útil para conexões em rede. Seu sistema precisará de uma maneira de detectar uma quebra de rede muito rapidamente, para evitar perda de dados. Para espera ativa em sistemas de alta velocidade com taxas de atualização de dados rápidas, a detecção de tempo limite com uma taxa de resposta de subsegundos é essencial.
Em qualquer evento, o sistema deve ser capaz de detectar um tempo limite para uma conexão de rede com falha, bem como uma falha no recebimento de dados. Essa distinção é importante. Pode levar segundos ou até minutos para detectar uma falha de comunicação, mas um gerenciador de redundância deve ser capaz de detectar uma interrupção do fluxo de dados em um período de tempo muito próximo da taxa de dados real do sistema físico. O gerenciador de redundância deve ser capaz de alternar de uma fonte para outra com base apenas na observação de que os dados não chegaram da conexão primária, mas sim do sistema de backup.
Alguns sistemas usam tempos limite de COM para monitoramento de link. Isso pode ser aceitável para circunstâncias em que interrupções de dados relativamente longas são toleráveis, mas não recomendamos confiar em tempos limite de COM para warm ou cold standby.
Mudança inteligente
O comportamento do sistema de redundância durante uma transição pode ser significativo. Por exemplo, suponha que as conexões primária e secundária falharam por algum motivo. Um gerenciador de redundância típico iniciará um ciclo de tentativa de conexão a um e depois ao outro servidor OPC até que um deles responda. O gerenciador de redundância alternará entre os dois indefinidamente, injetando períodos de suspensão entre cada flip-flop para reduzir a carga de recursos do sistema. Este período de sono é em si uma fonte de latência. Um modelo de alternância mais inteligente é manter um status de integridade da fonte que permita que o gerenciador de redundância faça a alternância somente quando o status da origem for alterado. Isso permite que o gerenciador de redundância fique efetivamente inativo ou execute tentativas simultâneas de reconexão até que o status de uma fonte mude e, em seguida, responda imediatamente sem introduzir latência extra. Uma lógica de comutação mais inteligente pode resultar em carga do sistema e tempos de comutação substancialmente reduzidos.
Troca forçada vs. Fonte preferencial
É útil poder selecionar uma fonte de dados em vez de outra, mesmo que a fonte atualmente anexada esteja íntegra. Um gerenciador de redundância ingênuo “forçará” o usuário a mudar, mesmo que o sistema de backup não esteja disponível. Isto resultará novamente em um comportamento de flip-flop quando o gerenciador de redundância tentar mudar para a fonte de backup indisponível. Uma abordagem muito melhor é o gerenciador de redundância entender o conceito de uma fonte preferencial que pode ser alterada em tempo de execução. Se a fonte preferida estiver disponível, o gerenciador de redundância mudará para ela. Se o usuário quiser mudar de uma fonte para outra, basta alterar a fonte preferida. Se essa fonte estiver disponível, a troca será feita. Caso contrário, o gerenciador de redundância fará a troca somente quando estiver disponível. Isso elimina o comportamento do flip-flop e, ao mesmo tempo, elimina a perda de dados associada ao mínimo de dois ciclos de comutação que o gerenciador de redundância ingênuo irá impor.
Acessando dados brutos
Um bom sistema de redundância a quente dará ao aplicativo cliente acesso não apenas aos dados redundantes, mas também aos dados brutos de ambas as fontes. Isto dá à aplicação cliente a opção de apresentar informações de diagnóstico sobre o sistema no “lado distante” do gerenciador de redundância. A maioria dos gerenciadores de redundância oculta essas informações para que um aplicativo cliente tenha que fazer e gerenciar diversas conexões para acessar os dados brutos, se isso for possível.
Outras opções e recursos
Além dos recursos acima, um bom gerenciador de redundância pode oferecer recursos adicionais para sua conveniência. Pode fornecer a opção de atualizar todo o conjunto de dados na transição. Talvez envie e-mails ou até mesmo lance programas adicionais a cada transição. Isto pode ser útil para notificar o pessoal-chave sobre o status do sistema. Ele pode registrar diagnósticos para fornecer informações valiosas sobre os motivos da mudança. Alguns gerenciadores de redundância podem se conectar a vários servidores e criar diversas conexões redundantes. Outros podem permitir que você trabalhe com subconjuntos de dados. Outro recurso desejável é a capacidade de atribuir as fontes de dados primárias e secundárias e de acionar um retorno da fonte de dados secundária para a primária assim que o problema que causou a alternância for resolvido.
À medida que os sistemas de controlo continuam a crescer em complexidade e à medida que confiamos cada vez mais neles, a situação de Mel Farnsworth tornar-se-á mais comum e mais dispendiosa. Se a conectividade de dados for crucial para o sucesso da empresa, seria sensato considerar a possibilidade de instalar um sistema redundante e levar em conta as considerações acima ao implementar a redundância para OPC.
Skkynet®, DataHub®, SkkyHub™, WebView™, os logotipos Skkynet e DataHub são marcas registradas ou marcas comerciais usadas sob licença pelo grupo de empresas Skkynet (“Skkynet”).
Todos e quaisquer direitos de propriedade intelectual associados ao presente documento e ao seu conteúdo (incluindo, mas não se limitando a: texto, relatório, planilha, apresentação, imagens gráficas, marcas registradas, logotipos, traduções, etc.) são de propriedade exclusiva da PARAGON TECNOLOGIA LTDA.. Nesse sentido, o conteúdo não pode, sob qualquer pretexto, ser vendido, cedido, distribuído, transmitido, copiado, modificado ou descompilado, de qualquer forma, sem o Consentimento prévio, e por escrito, da PARAGON TECNOLOGIA LTDA.. Ademais, qualquer uso não autorizado do conteúdo é expressamente proibido e pode constituir uma violação da lei.